高性能计算环境下复杂深度学习离线训练的数据处理服务
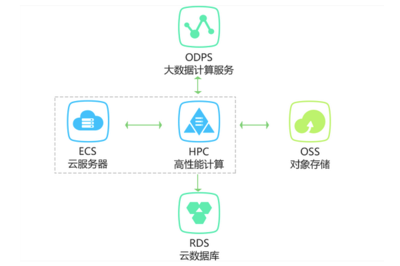
在高性能计算(HPC)环境中,复杂深度学习模型的离线训练对数据处理服务提出了极高要求。这些服务负责高效、可靠地准备和管理海量数据,确保训练过程的稳定与模型性能的优化。以下介绍几种关键的数据处理服务及其在高性能深度学习训练中的应用。
1. 分布式数据存储与管理
高性能计算系统通常采用分布式文件系统(如Lustre、GPFS)或对象存储(如Ceph)来管理大规模数据集。这些系统支持并行读写,能够快速加载TB甚至PB级数据,满足多节点训练时的数据访问需求。数据处理服务负责数据的组织、索引和备份,确保数据可用性与完整性。
2. 数据预处理与增强
离线训练前,原始数据需经过清洗、归一化、标注和增强等处理。在高性能计算环境中,数据处理服务利用并行计算框架(如Apache Spark、Dask)或专用GPU加速库(如NVIDIA DALI)实现高效预处理。例如,图像数据可通过随机裁剪、旋转和颜色变换进行增强,提升模型泛化能力;文本数据则需进行分词、向量化等操作。
3. 数据流水线优化
为减少训练过程中的I/O瓶颈,数据处理服务构建高效的数据流水线,实现数据加载与模型训练的异步并行。工具如TensorFlow的tf.data或PyTorch的DataLoader支持数据预取和缓存,将处理后的数据直接送入GPU内存。在高性能计算集群中,流水线还可结合MPI或NCCL实现跨节点数据分发,进一步提升吞吐量。
4. 数据版本控制与元数据管理
复杂深度学习项目常涉及多次实验和数据集迭代。数据处理服务集成版本控制系统(如DVC)和元数据管理工具(如ML Metadata),跟踪数据来源、处理历史及版本变化。这有助于重现训练结果,优化数据策略,并符合科研或工业场景的合规要求。
5. 容错与弹性处理
高性能计算环境可能因节点故障或网络问题导致训练中断。数据处理服务需具备容错机制,例如通过检查点(Checkpointing)保存中间状态,或使用弹性数据存储(如Alluxio)保证数据可恢复性。服务应支持动态扩缩容,以适应计算资源的变化。
6. 异构数据支持与跨格式转换
深度学习应用常涉及多模态数据(如图像、文本、视频)。数据处理服务需支持异构数据的统一管理,并提供格式转换工具(如将RAW图像转为TFRecord或HDF5),优化存储效率与读取速度。在高性能计算系统中,这可结合高速网络(如InfiniBand)实现低延迟数据传输。
7. 数据安全与隐私保护
针对敏感数据(如医疗或金融信息),数据处理服务集成加密、访问控制和匿名化技术。例如,使用同态加密或差分隐私方法在训练过程中保护数据隐私,同时符合GDPR等法规要求。
高性能计算下的深度学习离线训练依赖于高度优化的数据处理服务。这些服务通过分布式存储、并行预处理、流水线优化和容错机制,有效解决了海量数据管理的挑战,为复杂模型的训练提供坚实基础。随着AI与HPC的深度融合,数据处理服务将进一步向自动化、智能化和可持续化方向发展。
如若转载,请注明出处:http://www.lenovoyangtian.com/product/19.html
更新时间:2026-04-16 20:01:01