日处理20亿数据 实时用户行为服务系统架构实践
在大数据时代,处理海量用户行为数据并实现实时分析已成为企业提升用户体验和业务决策的关键。本文将介绍一个日处理20亿条数据的实时用户行为服务系统架构实践,涵盖数据采集、传输、存储、计算及可视化等核心环节。
一、系统架构概述
该实时用户行为服务系统采用分层架构设计,主要包括数据采集层、数据传输层、数据处理层、数据存储层和应用服务层。系统通过分布式技术保证高可用性和可扩展性,确保在数据量激增时仍能稳定运行。
二、数据采集层
数据采集层负责从各类客户端(如Web、App、小程序等)收集用户行为数据。采用轻量级SDK嵌入客户端,通过异步方式上报事件数据,避免阻塞用户操作。同时,支持多种数据格式(如JSON、Avro),并利用数据压缩和批量上传策略减少网络开销。日均采集数据量达20亿条,峰值QPS超过50万。
三、数据传输层
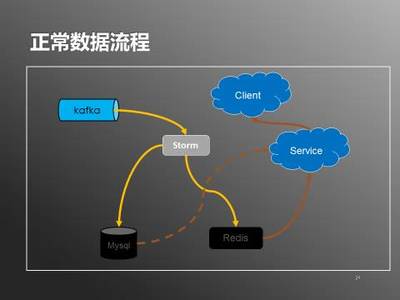
数据传输层使用高吞吐量的消息队列(如Kafka)作为数据管道,确保数据可靠、有序地传递。Kafka集群采用多副本机制,防止数据丢失,并通过分区策略实现负载均衡。数据在此层进行初步过滤和格式标准化,为后续处理做好准备。
四、数据处理层
数据处理层是系统的核心,采用流处理框架(如Apache Flink)进行实时计算。Flink作业消费Kafka中的数据,执行用户行为分析、聚合、去重等操作,并支持复杂事件处理(CEP)以识别特定模式。计算结果实时写入存储层,同时将指标数据推送至监控系统,便于运维人员实时追踪系统状态。
五、数据存储层
数据存储层分为实时存储和历史存储两部分。实时数据存储使用OLAP数据库(如ClickHouse)或时序数据库(如InfluxDB),支持低延迟查询和多维分析;历史数据则存入数据仓库(如Hadoop HDFS)或云存储,用于离线分析和模型训练。通过数据生命周期管理,自动迁移冷数据,优化存储成本。
六、应用服务层
应用服务层通过API网关对外提供数据服务,支持实时查询、仪表盘展示和告警功能。前端应用(如数据大屏、报表系统)通过RESTful API或WebSocket获取数据,并以图表形式直观呈现用户行为趋势。系统集成机器学习平台,实现个性化推荐和异常检测等高级功能。
七、监控与运维
为保障系统稳定性,我们建立了全面的监控体系,包括资源监控(CPU、内存、网络)、业务指标监控(处理延迟、数据准确性)和日志追踪。采用容器化部署(如Kubernetes)和自动化运维工具,实现快速扩缩容和故障自愈。
八、实践经验与优化
在实践中,我们面临了数据倾斜、网络延迟和资源争用等挑战。通过优化数据分区策略、引入缓存机制和调整计算逻辑,系统性能得到显著提升。未来,我们将探索边缘计算和AI驱动的自动化运维,以应对更大规模的数据处理需求。
该实时用户行为服务系统通过分层架构和先进技术栈,实现了日均20亿数据的高效处理与实时分析,为企业业务增长提供了坚实的数据支撑。随着技术的演进,系统将持续优化,以满足日益复杂的业务场景。
如若转载,请注明出处:http://www.lenovoyangtian.com/product/2.html
更新时间:2026-04-16 01:32:43